Array iteration performance in C#

EDIT: Updated to .NET 8 and improved content.
Implementing the sum of the items in an array is very simple. I think most developers would implement it this way:
static int Sum(int[] array)
{
var sum = 0;
for (var index = 0; index < array.Length; index++)
sum += array[index];
return sum;
}There’s actually a simpler alternative in C#:
static int Sum(int[] array)
{
var sum = 0;
foreach (var item in array)
sum += item;
return sum;
}One other alternative is to use the Sum() operation provided by LINQ. It can be applied to any enumerable, including arrays.
So, how do all these three fair in terms of performance?

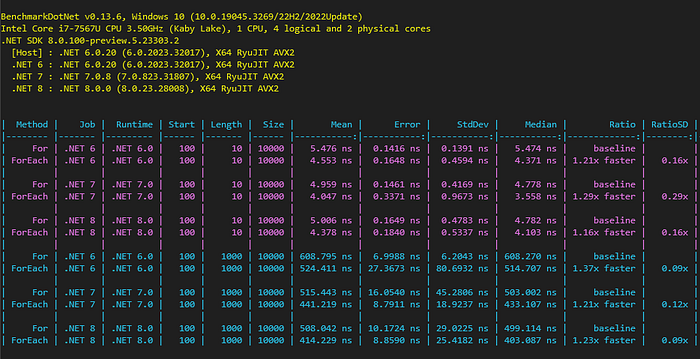
The benchmark compares the performance for arrays on int, with sizes 10 and 1.000, on .NET 6, 7, and 8.
You can see that, using a foreach loop can be around 30% faster than using a for loop.
LINQ implementation improved considerably in the latest .NET releases. It’s much slower in .NET 6, but a lot less slow in .NET 7 and considerably faster for large arrays in .NET 8.
Foreach
How can foreach be faster than a for loop?
Both for and foreach loops are syntactic sugar for a while loop. The compiler actually generates very similar code when these are used on a array.
You can see in SharpLab that for the following code:
var array = new[] {0, 1, 2, 3, 4, 5 };
Console.WriteLine(Sum_For());
Console.WriteLine(Sum_ForEach());
int Sum_For()
{
var sum = 0;
for (var index = 0; index < array.Length; index++)
sum += array[index];
return sum;
}
int Sum_ForEach()
{
var sum = 0;
foreach (var item in array)
sum += item;
return sum;
}The compiler generates the following:
[CompilerGenerated]
private static int <<Main>$>g__Sum_For|0_0(ref <>c__DisplayClass0_0 P_0)
{
int num = 0;
int num2 = 0;
while (num2 < P_0.array.Length)
{
num += P_0.array[num2];
num2++;
}
return num;
}
[CompilerGenerated]
private static int <<Main>$>g__Sum_ForEach|0_1(ref <>c__DisplayClass0_0 P_0)
{
int num = 0;
int[] array = P_0.array; // copy array reference
int num2 = 0;
while (num2 < array.Length)
{
int num3 = array[num2];
num += num3;
num2++;
}
return num;
}The code is very similar but notice that the foreach adds a reference to the array as a local variable. This allows the JIT compiler to remove bounds checking which makes the iteration much faster. Check the differences in the assembly generated:
Program.<<Main>$>g__Sum_For|0_0(<>c__DisplayClass0_0 ByRef)
L0000: sub rsp, 0x28
L0004: xor eax, eax
L0006: xor edx, edx
L0008: mov rcx, [rcx]
L000b: cmp dword ptr [rcx+8], 0
L000f: jle short L0038
L0011: nop [rax]
L0018: nop [rax+rax]
L0020: mov r8, rcx
L0023: cmp edx, [r8+8]
L0027: jae short L003d
L0029: mov r9d, edx
L002c: add eax, [r8+r9*4+0x10]
L0031: inc edx
L0033: cmp [rcx+8], edx
L0036: jg short L0020
L0038: add rsp, 0x28
L003c: ret
L003d: call 0x000002e975d100fc
L0042: int3
Program.<<Main>$>g__Sum_ForEach|0_1(<>c__DisplayClass0_0 ByRef)
L0000: xor eax, eax
L0002: mov rdx, [rcx]
L0005: xor ecx, ecx
L0007: mov r8d, [rdx+8]
L000b: test r8d, r8d
L000e: jle short L001f
L0010: mov r9d, ecx
L0013: add eax, [rdx+r9*4+0x10]
L0018: inc ecx
L001a: cmp r8d, ecx
L001d: jg short L0010
L001f: retThis results in the improved performance found in the benchmarks.
Notice in SharpLab that is the array is already a local variable, the copy is not generated. In this case, the performance is equivalent.
Slicing an array
Sometimes we may want to iterate just a portion of the array. Once more, I think most developers would implement the following:
static int Sum(int[] source, int start, int length)
{
var sum = 0;
for (var index = start; index < start + length; index++)
sum += source[index];
return sum;
}This can easily be converted to a foreach by using the Span.Slice() method:
static int Sum(int[] source, int start, int length)
=> Sum(source.AsSpan().Slice(start, length));
static int Sum(ReadOnlySpan<int> source)
{
var sum = 0;
foreach (var item in source)
sum += item;
return sum;
}So, how do these fairs in terms of performance?
Using foreach on a slice of the array also performs around 20% better than using the for loop.
LINQ
Checking the source code for the Sum() in System.Linq, for .NET versions prior to .NET 8, you’ll find that it uses a foreach loop. So, if using a foreach is faster than a for, why is it so slow in this case?
This implementation of Sum() is an extension method for the type IEnumerable<int>. Unlike the Count() and Where() operations, Sum() didn’t have a special case for when the source in an array. The compiler converts this implementation to something like this:
static int Sum(this IEnumerable<int> source)
{
var sum = 0;
IEnumerator<int> enumerator = source.GetEnumerator();
try
{
while(enumerator.MoveNext())
sum += enumerator.Current;
}
finally
{
enumerator?.Dispose()
}
return sum;
}There are several performance issues with this code:
GetEnumerator()returnsIEnumerator<T>. This implies that the enumerator is a reference type which means it has to be allocated on the heap, adding pressure to the garbage collector.IEnumerator<T>derives fromIDisposable. It then requires atry/finallyto dispose the enumerator, making it impossible to inline this method.- The iteration on an
IEnumerable<T>, requires calls to theMoveNext()method and theCurrentproperty. As the enumerator is a reference type, these calls are virtual.
All this makes the enumeration of the array much slower.
NOTE: Check my other article “Performance of value-type vs reference-type enumerators” to understand the difference in performance between these two types of enumerator.
.NET 8 performs much better because it optimizes Sum() when the source is an array or a List<T>. In the cases that it’s a array or list of int or long, it optimizes even more by using SIMD which allows the simultaneous sum of multiple items.
NOTE: Check my other article “Single Instruction, Multiple Data (SIMD) in .NET” to understand how SIMD works and how you can also use in your code.
Conclusions
Iteration of an array is a special case for the compiler which can perform code optimizations. The use of foreach guarantees the best conditions for these optimizations.
Converting an array to IEnumerable<T> makes its iteration a lot slower.
Not all LINQ methods are optimized for the case of arrays. Prior to .NET 8 it’s best to use a custom implementation of the Sum() method.
